
L’impiego dell’intelligenza artificiale, anche nei processi manifatturieri, ha fatto crescere enormemente la quantità di dati da elaborare, portando spesso alla situazione paradossale di avere troppi dati rispetto a quelli effettivamente gestibili dai sistemi informativi disponibili.
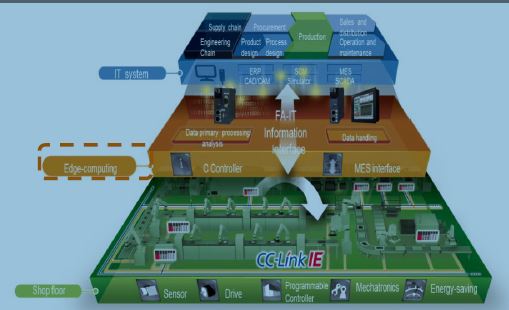 La risposta più “semplice”, per il mondo industriale, è stata quella di inseguire le tendenze dell’ICT, utilizzando il Cloud Computing. Questo ha portato ad affidare alla Rete (e quindi a sistemi distribuiti) l’elaborazione dei dati raccolti. Una soluzione che, da subito, ha mostrato i propri limiti. Primo tra tutti gli eccessivi tempi di trasmissione: un sistema Office può attendere una risposta per qualche secondo, mentre una linea industriale opera in Real Time e le latenze delle reti non possono essere tollerare. Ma ancora più devastante sarebbe un guasto alle reti di comunicazione, che impedirebbe il funzionamento delle linee di produzione.
La risposta più “semplice”, per il mondo industriale, è stata quella di inseguire le tendenze dell’ICT, utilizzando il Cloud Computing. Questo ha portato ad affidare alla Rete (e quindi a sistemi distribuiti) l’elaborazione dei dati raccolti. Una soluzione che, da subito, ha mostrato i propri limiti. Primo tra tutti gli eccessivi tempi di trasmissione: un sistema Office può attendere una risposta per qualche secondo, mentre una linea industriale opera in Real Time e le latenze delle reti non possono essere tollerare. Ma ancora più devastante sarebbe un guasto alle reti di comunicazione, che impedirebbe il funzionamento delle linee di produzione.
Dopo i primi deludenti tentativi di esternalizzare l’elaborazione dei dati, le aziende manifatturiere hanno così deciso di riportare all’interno parte di questi processi, sfruttando le potenzialità dell’Edge Computing. Ovvero un modello di architettura IT distribuita e decentralizzata, dove l’elaborazione dei dati avviene alla periferia della rete, vicino ai dispositivi che li hanno generati.
Avete le competenze?
Non si tratta, però, di un processo banale, poiché gli esperti dell’IT spesso non comprendono le reali esigenze dell’OT. Questa delicata transizione, infatti deve essere gestita con estrema prudenza. Infatti, come spiega il White paper gratuito Monitorare l’usura senza un sensore, “L’Edge computing isolerà il sistema IT dall’enorme massa di dati macchina, oltre a fornire la velocità e la sicurezza necessarie per le applicazioni di Factory Automation”.
In un mondo sempre più ricco d’informazioni da acquisire, l’uso dell’Edge Computing sembra essere l’unica strada percorribile anche per le applicazioni che richiedono l’accesso al Cloud.
Con tale strategia è possibile identificare le anomalie dei dati legate a problemi nel dispositivo e/o del processo, rispondere alle basse richieste di latenza e di privacy, oltre a fornire supporto per il filtraggio e sopperire all’archiviazione dei dati non immediatamente inviabili e/o richiesti dall’applicazione di alto livello”.
A cosa serve nella realtà?
Al di là delle indicazioni teoriche, il White paper gratuito Monitorare l’usura senza un sensore entra nello specifico di un caso reale: monitorare lo stato di usura di un ingranaggio sul quale sia impossibile installare direttamente un sensore.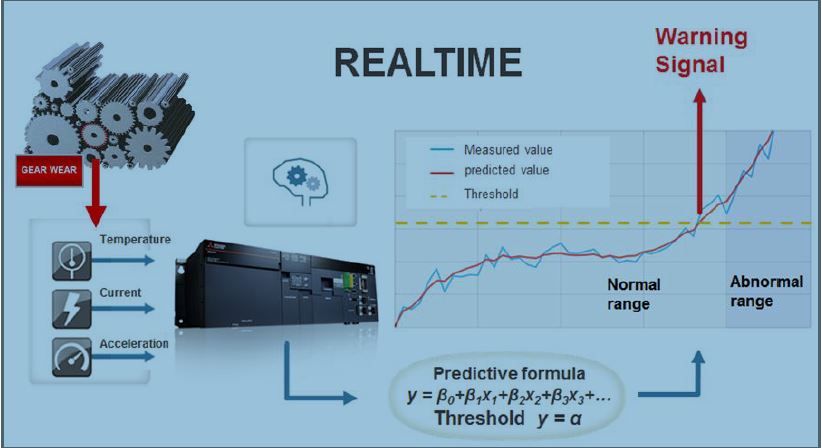
Per garantire un’adeguata manutenzione predittiva diventa infatti indispensabile raccogliere i dati misurabili attorno ad esso. In questa fase si ha bisogno di un esperto della macchina e del processo che si sta controllando”.
Questo perché è necessario comprendere e isolare i dati realmente utili all’analisi in questione. Una volta appurato che certe variabili sono in correlazione con l’usura del nostro ingranaggio, l’analisi fornirà la funzione di calcolo dell’usura teorica.
Tale funzione permetterà la stima predittiva dell’istante di rottura dell’ingranaggio e quindi potrà essere usata per segnalare in anticipo l’anomalia.
Per questo, come spiega il White Paper, viene istallato il sistema di raccolta dati e di diagnosi finale, capace di monitorare in tempo reale la predizione di guasto e inviare un allarme preventivo.